인공지능 기술이 비약적으로 발전하면서 의료, 금융, 자율주행 등 우리의 생명과 재산에 직결된 중요한 의사결정까지 AI가 담당하게 되었습니다.
하지만 기술이 고도화될수록 한 가지 치명적인 문제가 수면 위로 떠올랐습니다. 바로 ‘AI 블랙박스(Black Box)’ 문제입니다.
결과물은 놀라울 정도로 정확하지만, 정작 AI가 ‘왜’ 그런 판단을 내렸는지 개발자조차 설명하지 못하는 상황을 뜻합니다. 오늘은 이 블랙박스 문제가 왜 위험한지, 그리고 이를 해결하기 위해 인공지능 학계가 어떤 노력을 기울이고 있는지 자세히 알아보겠습니다.
1. AI 블랙박스 문제란 무엇인가?
블랙박스 문제는 딥러닝과 같은 복잡한 신경망 모델에서 주로 발생합니다.
인공지능 내부의 수억 개가 넘는 파라미터(매개변수)들이 서로 복잡하게 얽혀 연산을 수행하기 때문에, 데이터 입력부터 결과 출력 사이의 중간 과정을 인간의 논리로는 추적하기 어려운 현상을 말합니다.

- 성능과 설명력의 역설: 일반적으로 AI 모델의 성능(정확도)이 높을수록 모델의 구조는 복잡해지고, 반대로 설명 가능성(투명성)은 낮아집니다. 이를 ‘투명성-성능 패러독스(Transparency-Accuracy Paradox)’라고 부릅니다.
- 영리한 한스 효과(Clever Hans Effect): AI가 엉뚱한 근거로 정답을 맞히는 경우입니다. 예를 들어, 늑대와 개를 구분하는 AI가 동물의 특징이 아니라 배경에 깔린 ‘눈(Snow)’을 보고 늑대라고 판단한다면, 눈이 없는 곳의 늑대는 전혀 알아보지 못하게 됩니다. 내부 과정을 모르면 이런 치명적인 오류를 잡아낼 수 없습니다.
2. 설명할 수 없는 AI가 위험한 이유
단순한 추천 서비스라면 블랙박스 문제가 크지 않겠지만, 사회적 책임이 따르는 분야에서는 이야기가 달라집니다.
- 신뢰도와 책임 소재의 부재: 자율주행 자동차가 사고를 냈을 때, AI가 왜 그런 조작을 했는지 설명하지 못한다면 사고 원인 규명과 책임 소재 파악이 불가능해집니다.
- 편향성과 불공정성: 채용이나 대출 심사 AI가 특정 인종이나 성별에 편향된 판단을 내릴 경우, 그 근거를 알 수 없다면 사회적 차별을 정당화하거나 방치하는 결과를 초래할 수 있습니다.
- 의료 현장의 불확실성: 의사가 AI의 진단 결과를 환자에게 설명해야 하는데, “AI가 암이라고 하네요”라는 말 외에 의학적 근거를 제시하지 못한다면 실제 치료에 도입하기 어렵습니다.

3. 해결책: 설명 가능한 AI (XAI)
이러한 블랙박스 문제를 해결하기 위해 등장한 기술이 바로 ‘설명 가능한 AI(Explainable AI, XAI)’입니다.
결과의 근거를 인간이 이해할 수 있는 방식으로 제시하는 기술을 뜻합니다.
- 특징 중요도 시각화(Feature Importance): AI가 판단을 내릴 때 데이터의 어떤 부분에 가장 큰 가중치를 두었는지 보여줍니다. (예: 엑스레이 사진에서 폐의 특정 결절 부위를 강조 표시)
- LIME & SHAP: 복잡한 모델 전체를 설명하는 대신, 특정 결과 하나에 대해 “이 데이터 값이 조금 바뀌었다면 결과가 이렇게 달라졌을 것”이라는 방식으로 개별 판단의 근거를 설명합니다.
- 대리 모델(Surrogate Model): 복잡한 딥러닝 모델의 동작을 흉내 내는 아주 단순하고 이해하기 쉬운 모델(의사결정 나무 등)을 따로 만들어 전체적인 흐름을 파악합니다.
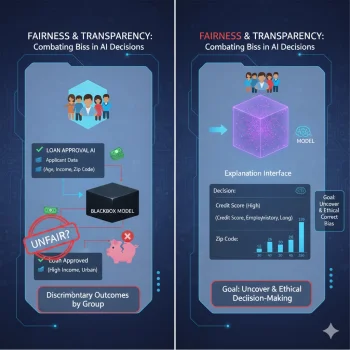
4. 결론: 투명성이 담보된 지능을 향해
AI의 성능이 인간을 능가하는 것만큼 중요한 것은 그 지능을 우리가 통제하고 신뢰할 수 있느냐는 점입니다.
블랙박스의 어둠을 걷어내고 AI의 사고 과정을 투명하게 밝히려는 XAI 연구는 기술적 완성을 넘어 윤리적이고 안전한 AI 시대를 열기 위한 필수 과정입니다.
앞으로 우리는 “정답을 맞히는 AI”를 넘어 “이유를 설명할 줄 아는 AI”와 공존하며 더 똑똑하고 공정한 세상을 만들어가게 될 것입니다.


